Introduction
Cluster analysis (or clustering) attempts to group observations into clusters so that the observations within a cluster are similar to each other while different from those in other clusters. It is often used when dealing with the question of discovering structure in data where no known group labels exist or when there might be some question about whether the data contain groups that correspond to a measured grouping variable. Therefore, cluster analysis is considered a type of unsupervised learning. It is used in many fields including statistics, machine learning, and image analysis, to name just a few. For a general introduction to cluster analysis, see Everitt and Hothorn (2011, Chapter 6).
Commonly used clustering methods are
-means
(MacQueen, 1967) and Ward’s hierarchical clustering (Murtagh and
Legendre, 2014; Ward, 1963), which are both implemented in functions
kmeans and hclust, respectively, in the
stats package in R (R Core Team, 2019). They belong to
a group of methods called polythetic clustering
(MacNaughton-Smith et al., 1964) which use combined information of
variables to partition data and generate groups of observations that are
similar on average. Monothetic cluster analysis (Chavent, 1998;
Piccarreta and Billari, 2007; Sneath and Sokal, 1973), on the other
hand, is a clustering algorithm that provides a hierarchical, recursive
partitioning of multivariate responses based on binary decision rules
that are built from individual response variables. It creates clusters
that contain shared characteristics that are defined by these rules.
In an application of clustering to Arctic sea ice extent data
comprising daily measurements from 1978 to present (Fetterer et al.,
2018), we faced a challenge choosing one splitting variable among
multiple equally qualified variables in monothetic clustering when
applied to functional data. This happens because there are very similar
observations in small intervals of time when the observations are smooth
curves. A new clustering algorithm called Partitioning Using Local
Subregions (PULS) that provides a method of clustering functional data
using subregion information is implemented in the R package
puls. It is designed to complement the
fda and fda.usc packages
(Febrero-Bande and Fuente, 2012; Ramsay et al., 2018) in clustering
functional data objects.
Partitioning Using Local Subregions (PULS)
Measurements taken over some ordered index such as time, frequency, or space and thought of as curves or functions of the index and/or other predictors are called functional data and denoted as (Ramsay and Silverman, 2005). Functional data have, possibly, a high frequency of observations over the index and are assumed to be generated by a smooth underlying process. Some examples of data that can be treated as functional include the growth curves for girls in the Berkeley Growth Study (Tuddenham and Snyder, 1954), hydraulic gradients in wetlands (Greenwood et al., 2011), or daily ice extent over years in the Arctic Sea (Fetterer et al., 2020). Clustering can be useful for functional data to find groups of curves sharing common characteristics and to find representative curves corresponding to different modes of variation in the data.
Functional clustering requires (1) construction of a functional data
object and (2) application of a clustering algorithm either to the
functional data directly or to a distance matrix calculated from the
functional data. In R (R Core Team, 2020), Ramsay et
al. (2018) created a package named fda to do the former
task and function metric.lp in fda.usc
(Febrero-Bande and Fuente, 2012) is designed to find the
distance matrix for functional data in the latter approach.
In some functional data applications, there is pre-existing knowledge
of regions of interest such as intervals of time where the curves are
expected to be very different from each other. Partitioning using local
subregions (PULS) is a clustering technique designed to explore
subregions of functional data for information to split the curves into
clusters. After defining the subregions
,
the Euclidean
()
distance is calculated between functions
and
(Febrero-Bande and Fuente, 2012) using the function
metric.lp in fda.usc to provide
and obtain a dissimilarity matrix for each subregion,
.
Adapting the idea of the monothetic clustering algorithm, each subregion
is separately considered as a splitting candidate for the next 2-group
partitioning, using commonly used clustering techniques such as
-means
(MacQueen, 1967), Ward’s method (Ward, 1963), or partitioning around
medoids (PAM, Kaufman and Rousseeuw, 1990). An inertia-like criterion is
again used as the global criterion for selecting each split. Among the
candidate splits, one from each subregion, the one having the largest
decrease in inertia will be chosen as the best split. The algorithm is
then recursively applied to the resulting sub-partitions until a
specified number of partitions is reached or a stopping rule is met.
The PULS algorithm was inspired by monothetic clustering and shares
many features such as inertia as the global criterion, a recursive
bi-partitioning method, and the same stopping rules. However, the idea
and applications of PULS are different enough to store in a separate
R package, which we named puls. Indeed,
puls borrows many private functions from
monoClust (Tran et al., 2020) such as the splitting
rule tree, recursively checking for the best splitting subregion,
tree-based displays of results, etc. An example of a usage of the main
function of the package, PULS, to the Arctic ice extent
data with subregions defined by months follows.
library(fda)
#> Loading required package: splines
#> Loading required package: fds
#> Loading required package: rainbow
#> Loading required package: MASS
#> Loading required package: pcaPP
#> Loading required package: RCurl
#> Loading required package: deSolve
#>
#> Attaching package: 'fda'
#> The following object is masked from 'package:graphics':
#>
#> matplot
#> The following object is masked from 'package:datasets':
#>
#> gait
library(puls)
# Build a simple fd object from already smoothed smoothed_arctic
data(smoothed_arctic)
NBASIS <- 300
NORDER <- 4
y <- t(as.matrix(smoothed_arctic[, -1]))
splinebasis <- create.bspline.basis(rangeval = c(1, 365),
nbasis = NBASIS,
norder = NORDER)
fdParobj <- fdPar(fdobj = splinebasis,
Lfdobj = 2,
# No need for any more smoothing
lambda = .000001)
yfd <- smooth.basis(argvals = 1:365, y = y, fdParobj = fdParobj)
Jan <- c(1, 31); Feb <- c(31, 59); Mar <- c(59, 90)
Apr <- c(90, 120); May <- c(120, 151); Jun <- c(151, 181)
Jul <- c(181, 212); Aug <- c(212, 243); Sep <- c(243, 273)
Oct <- c(273, 304); Nov <- c(304, 334); Dec <- c(334, 365)
intervals <-
rbind(Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec)
PULS4_pam <- PULS(toclust.fd = yfd$fd, intervals = intervals,
nclusters = 4, method = "pam")
plot(PULS4_pam)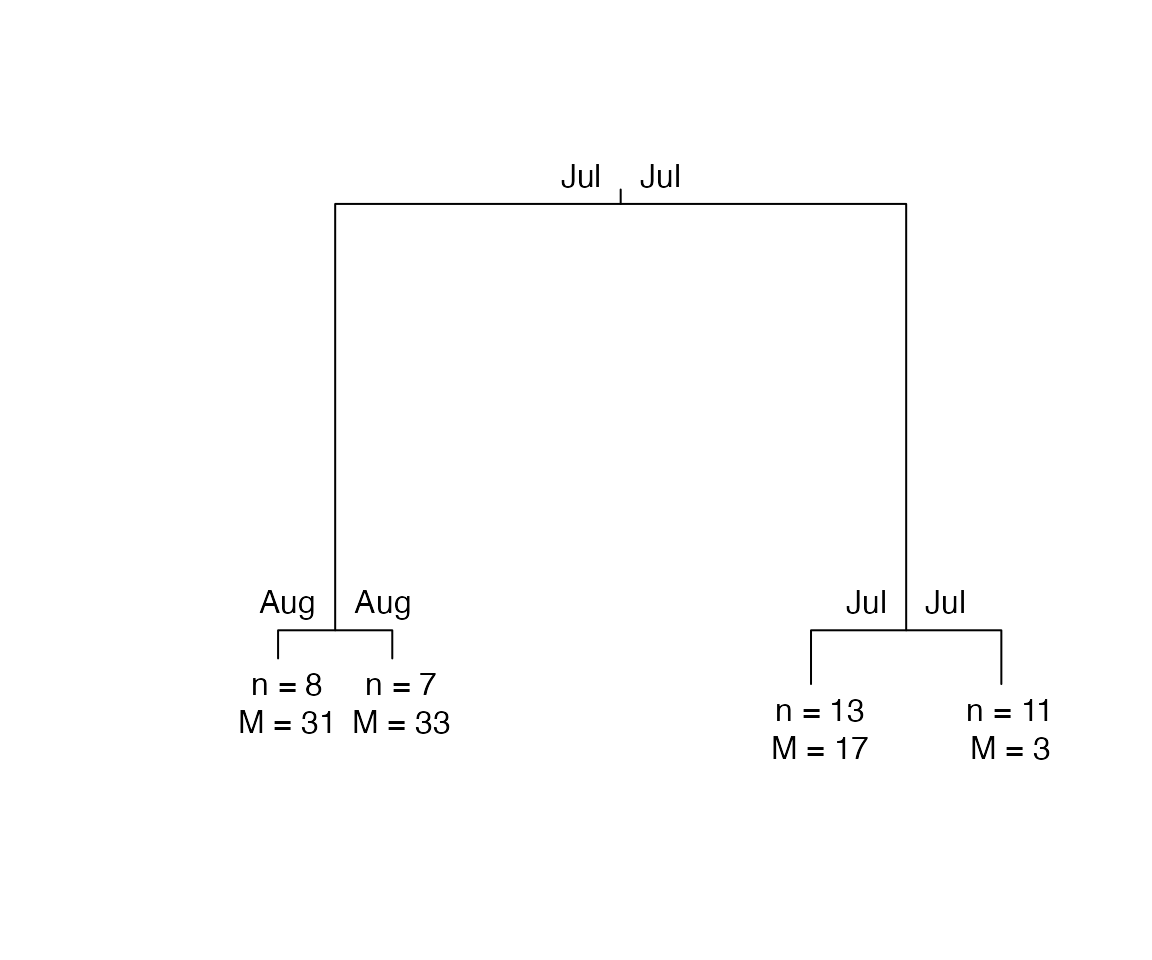
Four cluster result of PULS on Arctic ice extent data for years 1979-1986, 1989-2013.
The required arguments in PULS are an fd
object created by applying the smooth.basis function and
the list in a matrix of specified intervals for the subregions of
.
Other arguments in PULS function include:
-
method: the clustering method used to partition the subregions. It can be chosen between"pam"(for PAM method) and"ward"(for Ward’s method). -
distmethod: the method for calculating the distance matrix. It can be either"usc"for themetric.lpin fda.usc package (default) or"manual"for using the inner product of a very fine grid of values between two functions. -
labels: the name of entities -
nclusters: the desired number of clusters in the results -
minbucketandminsplit: the minimum number of observations that must exist in a node in order for a split to be attempted and the minimum number of observations allowed in a terminal leaf, respectively.
Constrained Version
In a data set, not all variables are created equal. Some variables are easier or cheaper to measure than others. For example, a data set on human vital information may include body fat percentage, height, and weight. Height and weight are much easier to obtain accurate measurements for than body fat percentage. If the data can be partitioned using only these easy-to-measure variables and the results are comparable to using all variables, it can help reduce effort and cost in the future studies where new subjects could be placed in clusters using easy or cheap to measure variables only.
PULS algorithm implemented in the puls packages have
options to limit the splitting candidates to a subset of variables (in
case of monothetic) or subregions (in case of PULS) by specifying the
argument spliton =. The following code limits the subset of
splitting variables only to summer months (August and September) of the
Arctic ice extent data. Besides the benefits of reducing effort and cost
in future studies, the constrained version of the algorithm also speeds
up the running time, making the cluster estimation faster.
constrained_PULS <- PULS(yfd$fd, intervals = intervals, nclusters = 4,
spliton = 7:9, method = "pam")
print(constrained_PULS)
#> n = 39
#>
#> Node) Split, N, Cluster Inertia, Proportion Inertia Explained,
#> * denotes terminal node
#>
#> 1) root 39 8453.2190 0.7072663
#> 2) Jul 15 885.3640 0.8431711
#> 4) Aug 8 311.7792 *
#> 5) Aug 7 178.8687 *
#> 3) Jul 24 1589.1780 0.7964770
#> 6) Jul 13 463.8466 *
#> 7) Jul 11 371.2143 *
#>
#> Note: One or more of the splits chosen had an alternative split that reduced inertia by the same amount. See "alt" column of "frame" object for details.Bibliography
- Chavent, M. (1998). “A monothetic clustering method”. In: Pattern Recognition Letters 19.11, pp. 989{996. issn: 01678655. .
- Everitt, B. and T. Hothorn (2011). An Introduction to Applied Multivariate Analysis with R. 1st ed. Springer. isbn: 1441996494.
- Febrero-Bande, M. and M. O. de la Fuente (2012). “Statistical Computing in Functional Data Analysis: The R Package fda.usc”. In: Journal of Statistical Software 51.4, pp. 1-28.
- Fetterer, F., F. Knowles, W. Meier, M. Savoie, and A. K. Windnagel (2020). Sea Ice Index, Version 3. . https://nsidc.org/data/g02135 (visited on 2020).
- Greenwood, M. C., R. S. Sojda, J. L. Sharp, R. G. Peck, and D. O. Rosenberry (2011). “Multi-scale Clustering of Functional Data with Application to Hydraulic Gradients in Wetlands”. In: Journal of Data Science 9.3, pp. 399-426.
- Kaufman, L. and P. J. Rousseeuw (1990). Finding Groups in Data: An Introduction to Cluster Analysis. 1st ed. Wiley-Interscience, p. 368. isbn: 978-0471735786.
- MacNaughton-Smith, P., W. T. Williams, M. B. Dale, and L. G. Mockett (1964). “Dissimilarity Analysis: a new Technique of Hierarchical Sub-division”. In: Nature 202.4936, pp. 1034-1035. issn: 0028-0836. .
- MacQueen, J. (1967). Some methods for classification and analysis of multivariate observations. Berkeley, Calif.
- Murtagh, F. and P. Legendre (2014). “Ward’s Hierarchical Agglomerative Clustering Method: Which Algorithms Implement Ward’s Criterion?” In: Journal of Classification 31.3, pp. 274-295. issn: 0176-4268.
- Piccarreta, R. and F. C. Billari (2007). “Clustering work and family trajectories by using a divisive algorithm”. In: Journal of the Royal Statistical Society: Series A (Statistics in Society) 170.4, pp. 1061-1078. issn: 0964-1998. .
- R Core Team (2020). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing. Vienna, Austria. https://www.R-project.org/.
- Ramsay, J. O. and B. W. Silverman (2005). Functional data analysis. Springer, p. 426. isbn: 9780387400808.
- Ramsay, J. O., H. Wickham, S. Graves, and G. Hooker (2018). fda: Functional Data Analysis. R package version 2.4.8.
- Sneath, P. H. A. and R. R. Sokal (1973). Numerical taxonomy: the principles and practice of numerical classification. W.H. Freeman, p. 573. isbn: 0716706970.
- Tan Tran, Brian McGuire, and Mark Greenwood (2020). monoClust: Perform Monothetic Clustering with Extensions to Circular Data. R package version 1.2.0. https://CRAN.R-project.org/package=monoClust
- Tuddenham, R. D. and M. M. Snyder (1954). “Physical growth of California boys and girls from birth to eighteen years.” In: Publications in child development. University of California, Berkeley 1.2, pp. 183-364.
- Ward, J. H. (1963). “Hierarchical Grouping to Optimize an Objective Function”. In: Journal of the American Statistical Association 58.301, pp. 236–244. issn: 0162-1459. .